O que significa unusual?
O que significa unusual? Uma palavra que se camufla entre o comum e o extraordinário, despertando a curiosidade e instigando a imaginação. É o toque de peculiaridade que nos faz questionar e explorar além dos limites do comum. É a beleza encontrada na diferença, no inesperado, no inusitado. É o convite para abraçar o incomum e descobrir o encanto que…

O que significa owner?
Quando pensamos em "owner", a primeira imagem que nos vem à mente é a de alguém que possui algo. Mas será que o significado é apenas esse? De forma criativa, exploraremos as nuances dessa palavra tão utilizada no mundo dos negócios e descobriremos que ser um "owner" vai além da simples posse, é ser o criador, o guia e o…

O que significa respect?
O que significa respeito? Uma palavra tão pequena, mas carregada de significado. Respeito é mais do que apenas tratar os outros com educação, é reconhecer sua individualidade, seu valor e suas limitações. É não julgar, mas sim aceitar. É ser gentil, empático e humilde. O respeito é a base de todos os relacionamentos saudáveis e de uma sociedade harmoniosa. É…



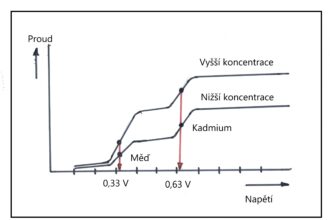


O que significa ter pressão alta?
A pressão alta, conhecida também como hipertensão, é como uma tempestade silenciosa…
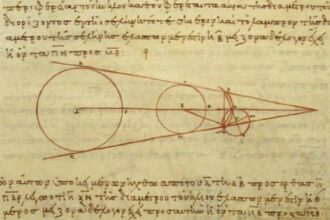








O que significa integral na matemática?
Você já se perguntou o que realmente significa "integral" na matemática? É…

O que significa equações polinomiais?
Você já se perguntou sobre o significado das equações polinomiais e como…

O que significa equação diferencial na matemática?
Resolver equações diferenciais pode ser desafiador para muitos estudantes de matemática, mas…
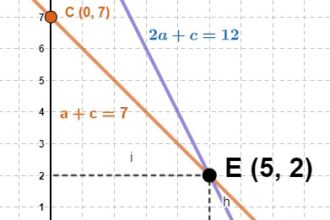
O que significa equação de 2º grau?
A equação de 2º grau, também conhecida como equação quadrática, é um…

O que significa função afim na matemática?
A função afim na matemática é como uma dança matemática encantadora, na…

O que significa cosseno na matemática?
O cosseno é uma das grandezas fundamentais da matemática, mas seu significado…


O que significa seno na matemática?
O seno, um dos mais enigmáticos termos da matemática, desperta curiosidade e…

O que significa capitalismo?
O que significa capitalismo? É um conceito que se desdobra em um verdadeiro oceano de interpretações e debates. Desde sua origem na Revolução Industrial até os dias atuais, o capitalismo abrange os pilares da propriedade privada, da livre iniciativa e do mercado competitivo. Mas, será que esse sistema econômico tem se mostrado eficiente e sustentável para todos? Exploraremos essas questões e muito mais neste artigo, mergulhando nas profundezas desse complexo sistema que molda nossa sociedade contemporânea.







O que significa NVM?
Você provavelmente já se deparou com a famosa abreviação "NVM" nas mensagens de texto ou em chats online. Mas, afinal, o que significa NVM? Descubra aqui o significado dessa expressão…