O que significa organize?
Organize, um termo tão simples, mas com significados tão profundos. É como se fosse um convite para colocar cada coisa em seu devido lugar, seja físico ou mentalmente. É criar ordem no caos, encontrar harmonia na bagunça. Organizar é dar sentido e propósito, trazendo equilíbrio para nossas vidas tão frenéticas. É um ato de cuidado e amor próprio, de nos…

O que significa plan?
No vasto oceano do destino, a palavra "plan" flutua como uma bússola, apontando para um destino incerto. Mas o que significa "plan"? É a manifestação de esperanças e sonhos, traduzida em estratégias meticulosamente elaboradas. É o mapa que guia nossa jornada, o projeto que transforma ideias em realidade. "Plan" é a essência do progresso, a promessa de um futuro melhor.

O que significa anxiety?
A ansiedade, um sentimento intenso e perturbador que pode nos dominar, tem raízes profundas em nossas preocupações e medos. Mas o que significa exatamente? É uma montanha-russa emocional, uma tempestade interior que nos desorienta e nos faz questionar. Descobrir sua real significância é mergulhar nas profundezas de nossas emoções.






O quê significar ser hipermineral?
O ser hipermineral é transcender as fronteiras do convencional, mergulhar no universo…









O que significa operação matemática?
Mergulhando no colorido mundo da matemática, nos deparamos com a pergunta: o…

O que significa acima na matemática?
Na matemática, a palavra "acima" ganha um novo significado. Deixando de ser…
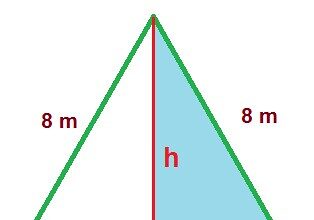
O que significa equilátero?
No mundo da geometria, a palavra "equilátero" evoca harmonia, perfeição e equidade.…

O que significa integral na matemática?
Você já se perguntou o que realmente significa "integral" na matemática? É…

O que significa relações trigonométricas?
Você já se perguntou o que significa relações trigonométricas? Esses conceitos matemáticos,…

O que significa vetor na matemática?
Quando entramos no mundo da matemática, nos deparamos com diversos conceitos e…
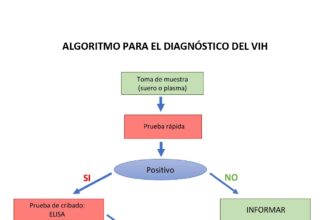
O que significa algoritmo na matemática?
Algoritmo na matemática é como uma incrível coreografia numérica, uma dança entre…
O que significa geometria na matemática?
Geometria, uma palavra que desperta curiosidade e desafia a imaginação. Na matemática,…

O que significa capitalismo?
O que significa capitalismo? É um conceito que se desdobra em um verdadeiro oceano de interpretações e debates. Desde sua origem na Revolução Industrial até os dias atuais, o capitalismo abrange os pilares da propriedade privada, da livre iniciativa e do mercado competitivo. Mas, será que esse sistema econômico tem se mostrado eficiente e sustentável para todos? Exploraremos essas questões e muito mais neste artigo, mergulhando nas profundezas desse complexo sistema que molda nossa sociedade contemporânea.







O que significa CPF?
CPF, a sigla que atormenta e confunde muitos brasileiros. Mas, afinal, o que significa CPF? São as iniciais de Cadastro de Pessoas Físicas, um número único e indispensável para a…