O que significa literature?
A palavra "literature" carrega consigo a beleza das palavras que inspiram e transportam o leitor para outros mundos. Mais do que meras histórias escritas, a literatura é a expressão da alma humana e a ponte que conecta culturas e gerações. Ela nos faz sonhar, refletir e nos questionar, sendo um reflexo da complexidade da vida. Deixa-se envolver por essa arte…

O que significa correspondent?
Você já se perguntou o que significa correspondent? Essa palavra tem origem no francês e se refere a uma pessoa ou empresa que representa um veículo de comunicação em uma determinada região. Um correspondente tem a importante função de relatar notícias, eventos e acontecimentos locais para seu veículo. Saiba mais sobre o significado e importância dos correspondentes neste artigo!

O que significa mean?
O que significa mean?" é uma pergunta comum para aqueles que estão aprendendo inglês. Mas o significado dessa pequena palavra vai muito além. Ela pode ser usada para expressar crueldade, mas também pode representar média ou intenção. Descubra as múltiplas faces da palavra "mean" e desvende seu verdadeiro significado.







O que significa câncer de rim, de bexiga ou de próstata?
O câncer de rim, de bexiga e de próstata são termos que…
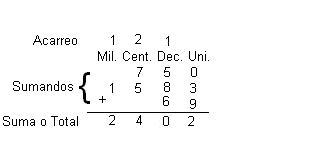





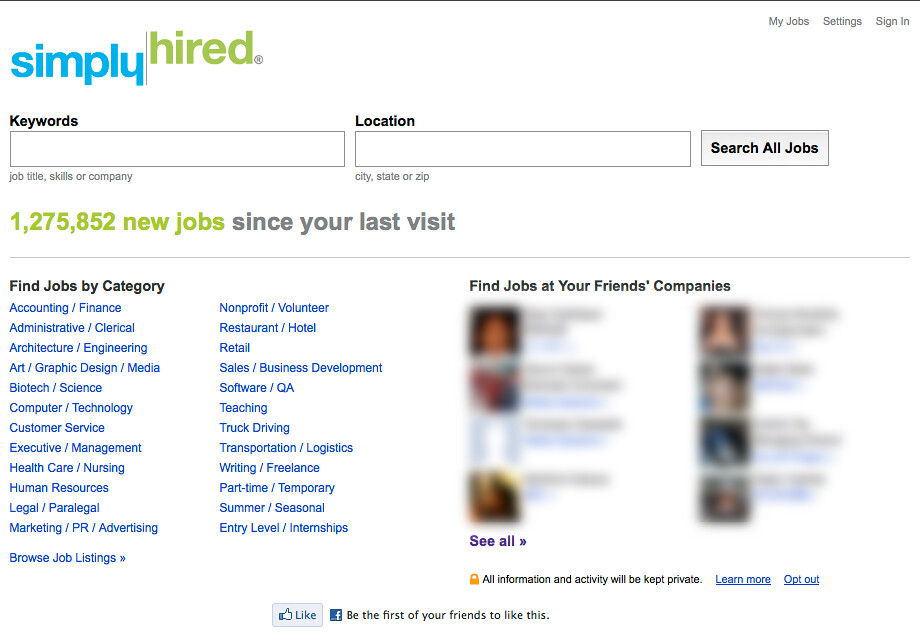


O que significa expressão numérica?
A expressão numérica, um enigma matemático envolto em símbolos, números e operações.…

O que significa relações trigonométricas?
Você já se perguntou o que significa relações trigonométricas? Esses conceitos matemáticos,…

O que significa subtração?
A subtração é um conceito matemático que pode parecer complicado à primeira…
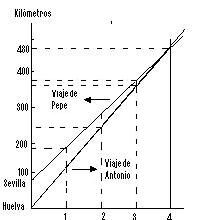

O que significa equações polinomiais?
Você já se perguntou sobre o significado das equações polinomiais e como…

O que significa zero na matemática?
Zero na matemática: Um Portal para o Infinito Aquele número solitário que…
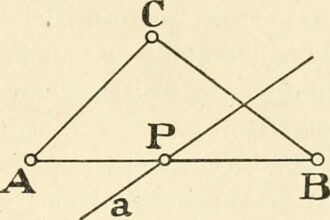
O que significa axioma na matemática?
Você já se perguntou o que significa axioma na matemática? Bem, prepare-se…
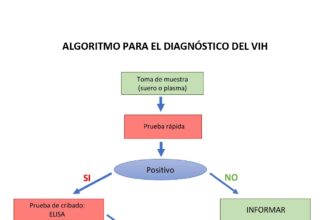
O que significa algoritmo na matemática?
Algoritmo na matemática é como uma incrível coreografia numérica, uma dança entre…

O que significa capitalismo?
O que significa capitalismo? É um conceito que se desdobra em um verdadeiro oceano de interpretações e debates. Desde sua origem na Revolução Industrial até os dias atuais, o capitalismo abrange os pilares da propriedade privada, da livre iniciativa e do mercado competitivo. Mas, será que esse sistema econômico tem se mostrado eficiente e sustentável para todos? Exploraremos essas questões e muito mais neste artigo, mergulhando nas profundezas desse complexo sistema que molda nossa sociedade contemporânea.







O que significa a sigla LGBTQIA+?
A sigla LGBTQIA+ representa a diversidade de identidades de gênero e orientações sexuais presentes na sociedade. Cada letra abraça uma expressão única, construindo uma comunidade unida em busca de igualdade…