O que significa resource?
O que significa resource? Essa pequena palavra carrega consigo um universo de significados e possibilidades. A própria essência da palavra remete à ideia de algo valioso, um recurso que pode ser utilizado para alcançar determinado objetivo. Em um mundo em constante transformação, entender como usar os recursos disponíveis é essencial para sobreviver e prosperar. Os recursos podem ser tangíveis ou…

O que significa lose?
Você já se perguntou o que significa "lose" em inglês? Essa simples palavra tem muito mais do que um significado literal. Venha descobrir as diferentes interpretações dessa palavra versátil e como utilizá-la corretamente em diversos contextos. Conheça os usos figurativos e emocionais de "lose" e amplie seu conhecimento no idioma!

O que significa technique?
A técnica é uma habilidade que envolve conhecimento, prática e destreza para realizar uma tarefa específica de forma eficiente. Saiba mais sobre o significado e importância da técnica em diferentes áreas de atuação.






O que significa doença de Crohn ou retocolite ulcerativa?
A doença de Crohn e a retocolite ulcerativa são condições crônicas que…










O que significa estatística na matemática?
A estatística na matemática é como uma lente que nos permite enxergar…
O que significa equações irracionais?
Você já se perguntou o real significado das equações irracionais? Elas são…
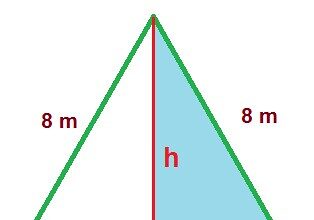
O que significa equilátero?
No mundo da geometria, a palavra "equilátero" evoca harmonia, perfeição e equidade.…

O que significa ângulo na matemática?
Na matemática, a palavra ângulo ganha vida própria. Ela se curva e…

O que significa operação matemática?
Mergulhando no colorido mundo da matemática, nos deparamos com a pergunta: o…

O que significa fator?
O fator, este enigma quase misterioso que permeia nosso universo matemático, representa…

O que significa assunto na matemática?
Matemática, a pedra angular do conhecimento numérico, muitas vezes nos desafia com…

O que significa geometria na matemática?
Geometria, uma palavra que desperta curiosidade e desafia a imaginação. Na matemática,…

O que significa capitalismo?
O que significa capitalismo? É um conceito que se desdobra em um verdadeiro oceano de interpretações e debates. Desde sua origem na Revolução Industrial até os dias atuais, o capitalismo abrange os pilares da propriedade privada, da livre iniciativa e do mercado competitivo. Mas, será que esse sistema econômico tem se mostrado eficiente e sustentável para todos? Exploraremos essas questões e muito mais neste artigo, mergulhando nas profundezas desse complexo sistema que molda nossa sociedade contemporânea.







O que significa FIES?
O Fundo de Financiamento Estudantil, conhecido como FIES, é um programa do governo brasileiro que surgiu para auxiliar estudantes a realizar o sonho de cursar o ensino superior. Com o…