O que significa armed?
Descobrir o significado de "armed" pode ser intrigante, à primeira vista. Essa palavra é frequentemente associada a armas e conflitos bélicos, porém possui diversas conotações. Desde estar "armado" com conhecimento até enfrentar desafios munido de coragem, "armed" revela-se como um termo multifacetado. Explorar suas nuances é uma maneira fascinante de compreender a complexidade da linguagem.

O que significa burn?
O termo "burn" pode ter várias interpretações, mas em sua essência, remete à sensação intensa de dor e sofrimento. Como uma chama que consome, o "burn" pode ser tanto uma manifestação física como emocional. Descubra mais sobre o significado multifacetado dessa palavra nesta fascinante exploração.

O que significa poor?
O que significa ser pobre?" Uma pergunta complexa que nos convida a refletir sobre as diversas dimensões dessa condição. Pobreza não é apenas uma falta de recursos materiais, mas também uma ausência de oportunidades e dignidade. Ser pobre é lutar contra a invisibilidade, enfrentar desigualdades e encontrar força para buscar um futuro melhor. O significado de ser pobre não pode…


















O que significa expressão numérica?
A expressão numérica, um enigma matemático envolto em símbolos, números e operações.…

O que significa equações exponenciais?
Você já se perguntou o que significam equações exponenciais? Essas equações misteriosas,…
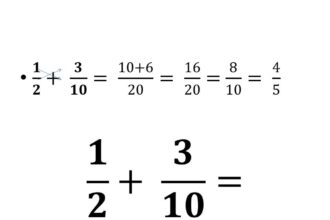
O que significa denominador?
Você já se perguntou o que significa denominador? Uma palavra tão peculiar…

O que significa argumento na matemática?
Na matemática, o termo "argumento" possui um significado peculiar. Ele refere-se à…
O que significa equações irracionais?
Você já se perguntou o real significado das equações irracionais? Elas são…

O que significa aproximação na matemática?
A aproximação na matemática é uma poderosa ferramenta que nos permite obter…
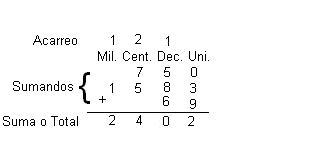

O que significa capitalismo?
O que significa capitalismo? É um conceito que se desdobra em um verdadeiro oceano de interpretações e debates. Desde sua origem na Revolução Industrial até os dias atuais, o capitalismo abrange os pilares da propriedade privada, da livre iniciativa e do mercado competitivo. Mas, será que esse sistema econômico tem se mostrado eficiente e sustentável para todos? Exploraremos essas questões e muito mais neste artigo, mergulhando nas profundezas desse complexo sistema que molda nossa sociedade contemporânea.






O que significa CFOP?
Se você já se perguntou o que significa CFOP, a resposta está aqui! CFOP, ou Código Fiscal de Operações e Prestações, é um código utilizado no Brasil para identificar e…